
Recursion is the act of defining something in terms of itself.
Think of two mirrors in front of each other. They will infinitely reflect each other.
You can also illustrate it statements such as: "To understand recursion, one first need to understand recursion".
A classic example from the arts is that of the *mise en abyme* technique, by which an artwork places a copy of itself within itself, hinting at an infinitely recurring sequence.
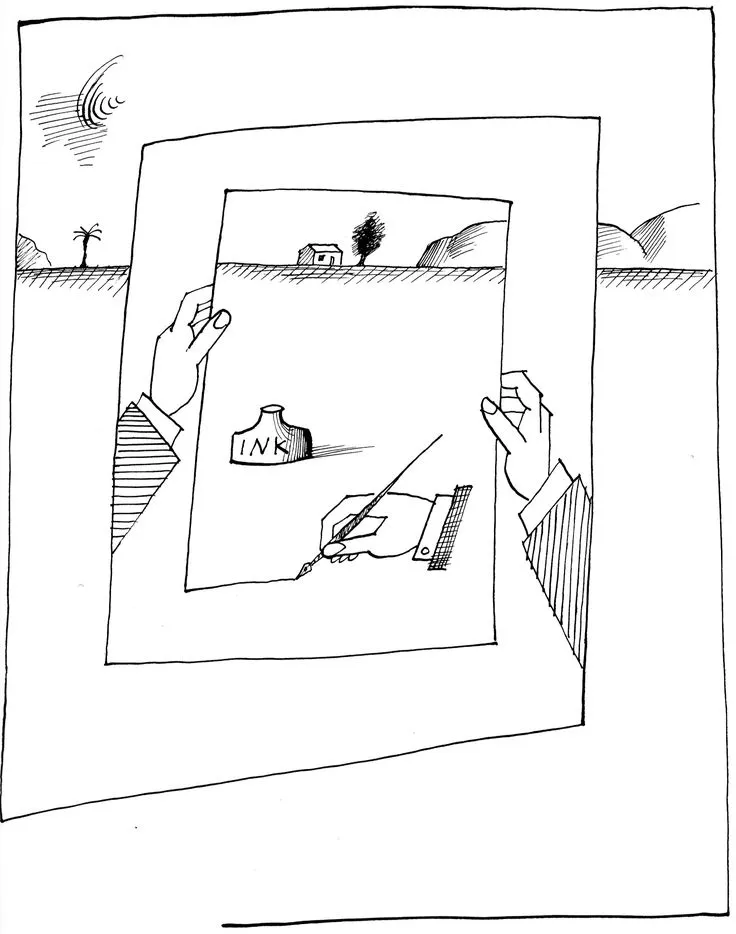
At a basic level, recursion can be thought of as a sort of paradox.
It's like going to your dictionary of choice, looking up the definition of the word egg, finding that it's where chicken come from. So you look up the definition for chicken, and find that chicken are what lay eggs.
If you want to know the definition of a "tool", and your dictionary gives you "A tool is a tool we can use to accomplish a task", you will go back and forth between the entry and its definition, because understanding the definition involves you looking at the definition of the word in terms of which the word has been defined.
On its own, this isn't very helpful. A recursive definition includes a **base case**, thus creating a simple yet powerful pattern that allow us to solve a surprising number of problems.
A base case is a condition that terminates the recursion when it's met.
Imagine you're programming a video game, where two mirrors can stand in front of each other. The mirrors are supposed to reflect whatever is in front of them, but you also don't want them to reflect each other infinitely.
Infinitely many operations isn't something that fits into your computer's memory, and no player will wait an infinite amount of time before each and every frame of the game.
To fix that, you use a base case. You could tell the computer to compute the reflection in each mirror until a reflection gets smaller than a pixel, or you could limit the numbers of reflection to a fixed number. Alternatively, of course, you could avoid putting mirrors in front of each other in the game.
Now that we have recursion and a base case, let's see how they work together and how we can create loops from them.
A classical example is factorial.
```cpp
#include <iostream>
int factorial(int n)
{
if (n <= 1) // base case
{
return 1;
}
return n * factorial(n - 1); // recursive step
}
int main()
{
int result = factorial(9); // 362880
std::cout << "The factorial of 9 is: " << result << std::endl;
}
```
The **call stack** is what makes recursion possible in software engineering. Every time a function is called, it's pushed onto the stack, until the base case is reached. Once that happens, the functions start to return and the results are unwound from the stack, allowing the values to be computed and returned up the chain.
The first thing that gets evaluated at the multiplication step is the recursive call. Before the function we're in can return, we must wait for that recursive step to return, which in turn must also wait for its recursive call to return... until there are no more calls to push onto the stack.
The stack has a limited size, so too many recursive calls creates a stack overflow and causes your program to crash. This is what you get if you forget to throw in a base case and create an accidental infinite loop.
You can think of the call stack as a pile of books inside a cabinet. You add books on books on books until your cabinet is filled. You can only grab the book that is on top if you want to grab subsequent books, following a Last-In, First-Out (LIFO) principle. The stack works the same way. Each recursive function call is like a new book placed on top.
We could extend the logic from our example to create a function `loop` that accepts a number `i` representing the total number of needed repetitions and a `fn` callback function that needs to be called upon each iteration.
The factorial example, while more intuitive because it is simple, doesn't provide any real benefits compared to an iterative version of the program.
Many applications, however, make much more sense when they're defined recursively.
Parsers, for instance, are often defined recursively, because it's much easier to think about the program that way. Otherwise you'd need loops within loops within loops...
[[Fixed Point of a Function|Fixed points]] of functions and *converging* series are defined recursively. You apply the same rule an infinite number of times. If you define a recurrence relation of $x_{n+1} = \sqrt x_n$ with an initial value of $x_0 = 2$, the result gets closer and closer to $1$ as you apply it. Apply it an infinite number of time, and you get exactly $1$. Set $x_0$ to *any* other number, and the thing happens as well.
Some recursive processes, on the other hand, *diverge*, often creating complex patterns like fractals ([[Overview of the Mandelbrot Set|Mandelbrot Set]], Sierpinski triangle, [[Cantor Set]]...).
Hopefully, now you understand how recursion works, and how you can use it.